When the Numbers Start Running the Work
- Shounak Bhattacharjee
- Feb 9
- 4 min read
Updated: May 10
How performance metrics quietly reshape professional judgement in public systems — and how to notice when they begin to do harm. INTERACTIVE TOOL below
Numbers are supposed to help-- In public systems, they’re usually introduced with reasonable intentions — to make work visible, to reduce arbitrariness, to show that decisions are being made fairly and consistently. A number can be tracked, explained, compared. It gives shape to things that would otherwise feel too subjective and too open to dispute.
In many ways, that matters. Without some form of measurement, systems drift. Patterns are harder to see. Accountability becomes uneven, and trust is harder to maintain. But over time, numbers don’t just sit alongside the work. They start to lean on it.
Gradually, often without anyone quite deciding it should be this way, performance measures begin to influence what feels legitimate to prioritise, what feels risky to attempt, and what feels safest to avoid. Not because people stop caring about outcomes, but because the system makes certain actions easier to justify than others — especially when time is short and scrutiny is expected.
This shift isn’t dramatic. It doesn’t arrive as a policy change or a formal instruction. It shows up in small adjustments: how a conversation is framed, which details are foregrounded, what gets written down and what stays implicit. What can be measured starts to feel more solid than what is harder to evidence, even when everyone involved knows that the harder-to-measure parts are doing much of the work.
I’ve seen this most clearly in public-facing services where decisions are made under pressure and with incomplete information. In those settings, metrics don’t remain neutral tools sitting outside professional judgement. They become part of how judgement itself is exercised. A target starts to function as a boundary — stay within this, and your decision is defensible. A performance indicator quietly replaces a more uncomfortable question about whether something was actually the right thing to do.
I see this tension clearly in crisis telephone services, where the work is relational, time-sensitive, and emotionally charged. In the service I work in at NHS England, performance is partly measured through things like how quickly calls are answered, whether follow-up surveys are completed, and how service users rate their experience at the end of the interaction.
On paper, these measures make sense. They’re designed to capture responsiveness, accessibility, and user satisfaction — all things that matter. But in practice, they can begin to pull judgement in subtle directions. Some callers contact the service repeatedly and arrive with a clear expectation of what they want to happen next. When that expectation isn’t met — even if the assessment is careful, clinically appropriate, and focused on safety — frustration can spill over into how the interaction is rated. A low score in those moments doesn’t necessarily reflect the quality of the work or the appropriateness of the response. It reflects disappointment, distress, or a sense of being unheard.
From the outside, the metric records dissatisfaction.
From the inside, something more complicated is happening.
Over time, those numbers still count. They feed into performance dashboards, service comparisons, and narratives about quality. And once they do, they start to matter in ways that are hard to ignore. Not because staff want to chase ratings, but because repeated negative scores — even when they’re predictable — have consequences for how a service is perceived and managed.
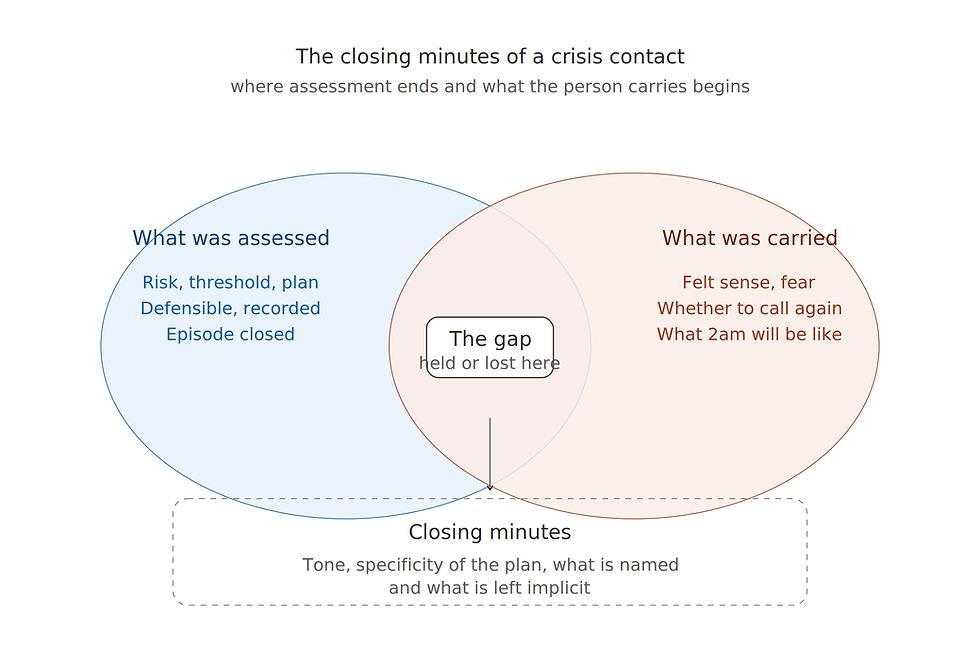
The risk, then, isn’t that people stop doing careful assessments. It’s that the system quietly starts privileging what can be scored over what can’t: emotional containment, boundary-setting, and decisions that are clinically sound but not immediately satisfying. The number captures a reaction. The work holds the risk. That gap — between what is measured and what is actually being carried — is where distortion begins.
This isn’t a story about people chasing numbers or trying to game the system. Most of the time, it’s the opposite. It’s about people trying to act responsibly within structures that reward some forms of attention and not others. The effect is subtle but cumulative. Judgement narrows. Risk doesn’t disappear so much as move elsewhere. And systems that were designed to support good decision-making begin, slowly, to reshape it.
Noticing when that is happening — and knowing how to respond before it causes harm — matters just as much as deciding what should be measured in the first place.
Try this as an interactive tool The questions below are also available as a guided diagnostic that walks through them one at a time, generates a distortion-risk profile for a measure you name, and produces a downloadable report.
PRACTITIONER TOOL
A simple stress test for performance measures
The questions below aren’t meant to replace performance metrics. They’re a way of slowing down just enough to notice when a measure may be shaping behaviour in unintended ways.
What behaviour does this measure actually reinforce?
Not what it’s designed to encourage, but what it reliably rewards under conditions of pressure, scrutiny, or limited time.
What this draws on: behavioural reinforcement, incentive salience, operant conditioning.
Which parts of the work become less visible when this measure takes priority?
Particularly judgement, emotional labour, coordination, or preventative work that doesn’t generate immediate outputs.
What this draws on: cognitive labour, emotional labour, task substitution, invisibility of effort.
Under what conditions could this measure be met while the underlying goal is compromised?
And how likely are those conditions in real operating environments?
What this draws on: proxy failure, ecological validity, Goodhart-type effects.
Who absorbs the risk when this measure is optimised in the wrong direction?
Is that risk shared, made explicit, or quietly displaced onto individuals or downstream services?
What this draws on: risk displacement, moral injury, organisational psychology.
How does this measure interact with professional judgement when the two diverge?
In practise, which one tends to carry more authority -- and what does that teach people over time?
What this draws on: authority gradients, normative pressure, professional identity.
What early signs would suggest this measure is starting to distort behaviour?
What would change first, and who would notice it before it appears in formal reports?
What this draws on: signal detection, sensemaking, leading vs lagging indicators.
Measurement will always be necessary in public systems. The question isn’t whether to use it, but how carefully it’s interpreted — especially when the work being done is complex, relational, and hard to reduce to a score. I’m interested in how systems can retain accountability without narrowing judgement, and how tools like this can support reflective decision-making rather than quietly replacing it.

System note · Measurement and behaviour

Comments